S3 Express Append has issues


AWS is clearly gearing up to make S3 Express a potential alternative to EBS disks. Like EBS, S3 Express is single zone. Earlier this year, AWS added the put-if-absent primitive to both S3 and S3 Express. Now it has released the ability to append to objects in S3 Express.
While append seems like another milestone towards disk-like behavior at first glance, a closer look reveals a more nuanced reality. To understand, let's look at the problems faced by S3-based distributed systems and how they solve them today.
Assume a distributed system writing directly to S3 Express. A node node-0 (original) is writing to a prefix /data/node-0/. If this node gets partitioned from the rest of the system, the system may create a new instance of node-0 (duplicate) while node-0 (original) is still active and communicating with S3. Leader Election is eventual, so this scenario could happen. Now we have two node-0 s in our system (original and duplicate). Both will try writing data to the /data/node-0/ prefix, causing serious data consistency issues.
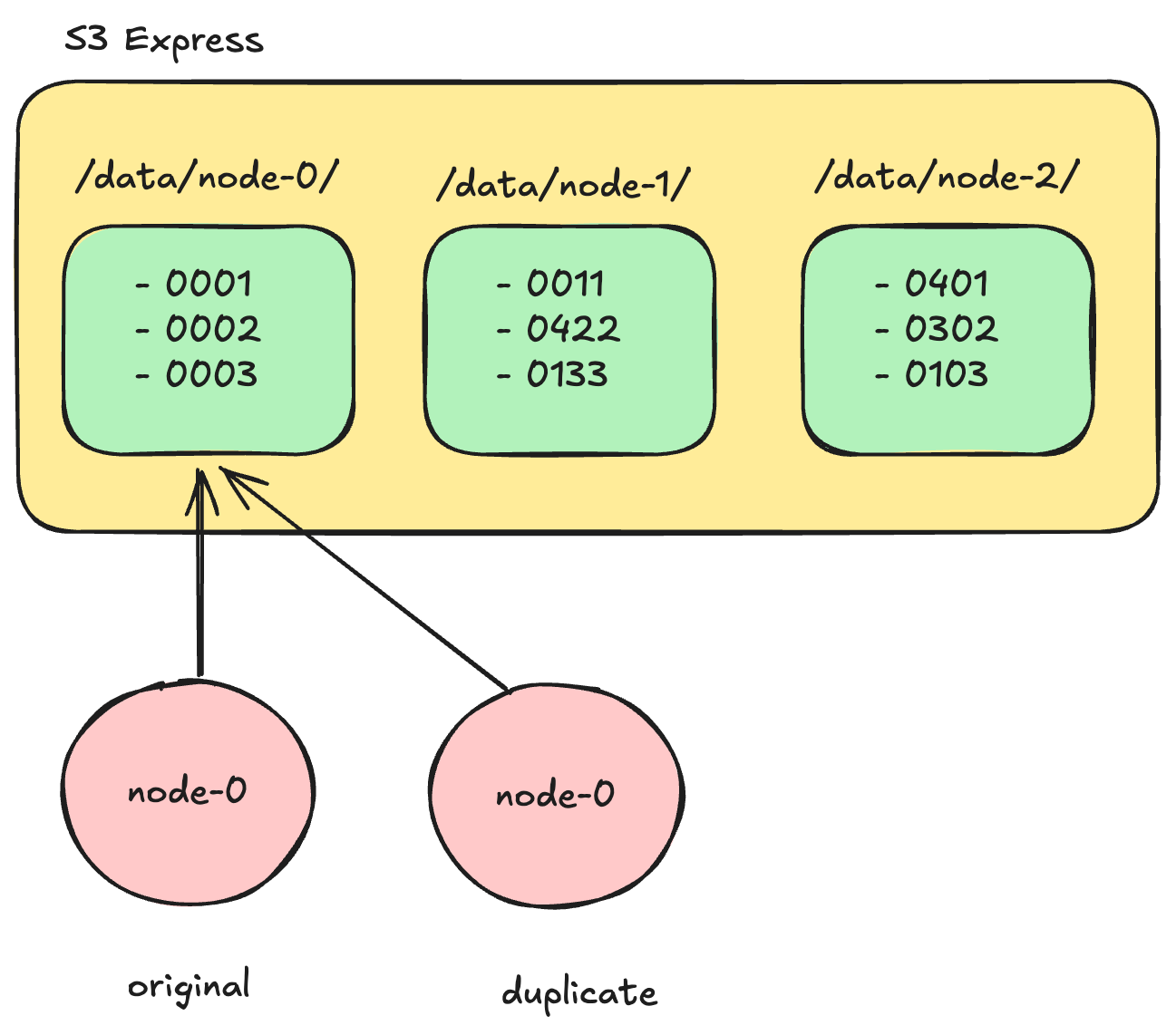
Data Lakehouse protocols like Delta Lake address the consistency issues described above. They ensure writes are made to new objects while incrementing a counter, e.g., 001 , 002, and so on. They use the put-if-absent primitive to detect if the object they are about to write has already been written. In this case, when one of the two node-0 tries to write an object like 003 using put-if-absent, it will detect that the object is already present (since it was written by the duplicate node-0 already), indicating that a new leader node has taken over, and the write will be rejected.
These protocols subsequently run background processes to walk these small objects sequentially and combine them into a larger checkpoint file. At this stage, the files can be transferred from S3 Express to S3 to reduce storage costs. Since this process is done as a background task, the latency of writing to S3 is a non-issue.
Append and its issues
The intended use for append in S3 Express is to allow systems to append to an existing object, like 002. Once the object is large enough, it can be moved from S3 Express to S3 to reduce storage costs. This approach eliminates the need for a background job to combine the files in memory.
However, this mechanism causes a problem with in distribtued systems with two node-0 instances can be present. Lets call them Node A & B. Say Node A is appending to 002 and after 10 appends, it gets partitioned from the system. A new leader node-0 Node B is elected. Node B sees that 002 exists, and starts writing to 003.
The issue arises when Node A adds its 11th append to 002. A can in fact continue to append to 002 until it reaches its size threshold. The system will not detect the leadership conflict until Node A attempts to write to 003. Only at this point, Node A will realized it is no longer the leader.
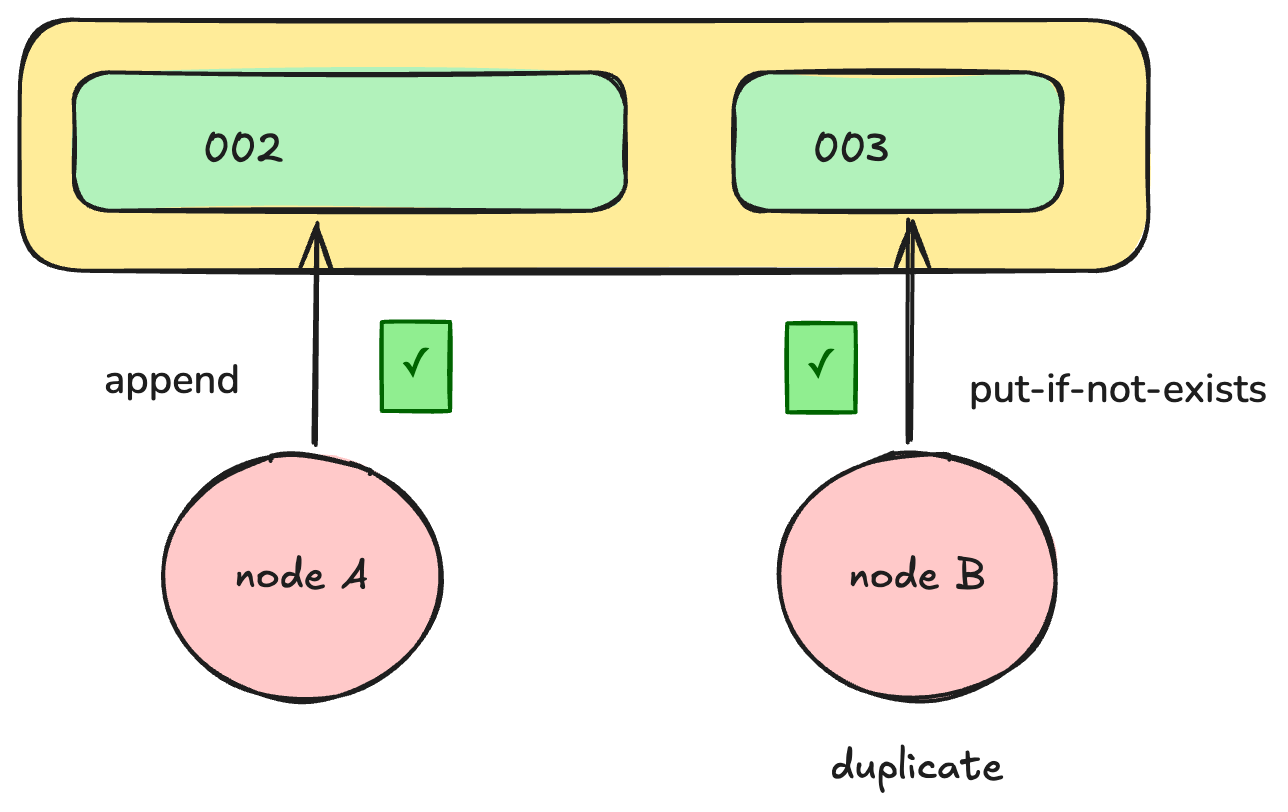
This results in invalid data in 002 as we cannot determine which appends to 002 were made after Node B began writing to 003. This creates data inconsistency within our system.
EBS disks work well for this case
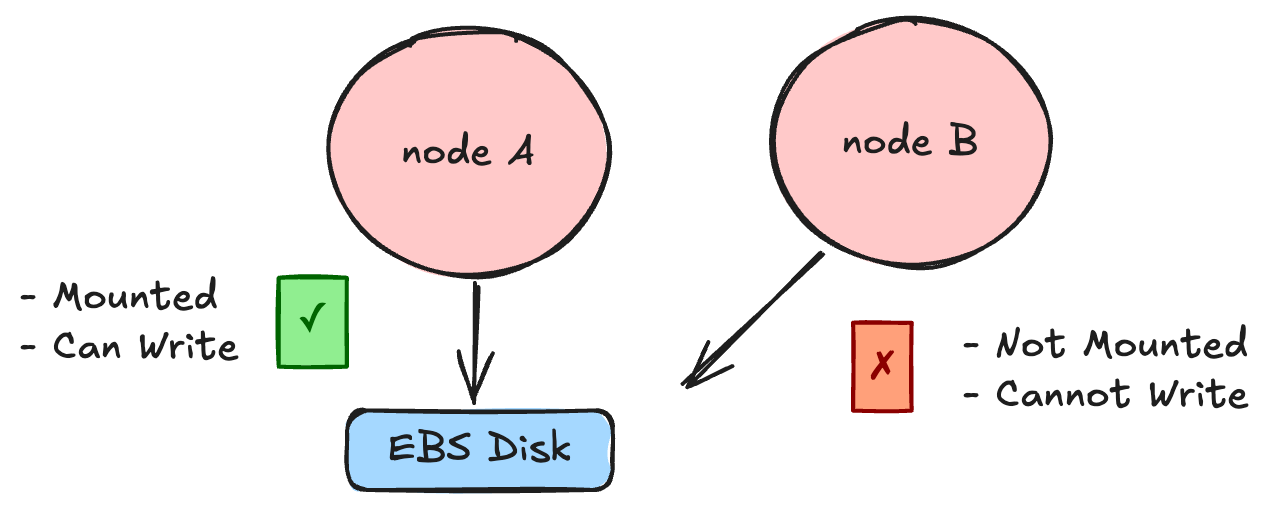
One of the defining characteristics of EBS disks, which makes them both convenient and cumbersome, is that they must be mounted to a node before any writes can occur. More critically, for another node to write to the same disk, the disk must first be unmounted from the previous node and mounted onto the new node.
This seemingly trivial fact has profound implications in distributed systems. With the disk mounted to Node A, it is impossible for Node B to write to the disk unless it has been explicitly detached from Node A. This design guarantees that two nodes cannot simultaneously write to the same disk, thereby preventing the issue of conflicting writes. As a result, appending to a disk in this setup works flawlessly.
As a potential thought bubble, for append to behave like EBS in S3 Express, AWS needs to introduce some form of per-prefix (short term) leases with queues. For example, Node A could hold a lease on /data/node-0/, effectively preventing other nodes from writing to this prefix. Node B could then join a queue to acquire the lease once Node A’s lease expires. This approach would allow Node B to safely take over as the leader while ensuring Node A retires without introducing inconsistencies.
From a cost perspective, append does not offer pricing advantages in S3 Express. You still get charged the price of a PUT call, meaning any potential benefits must come from reduced code complexity or savings in compute resources needed to combine objects in memory.
Even if append was made to somehow work in a consistent way, it would not completely eliminate the need for combining files in memory. Many scenarios, depending on algorithm, might require cutting over to a new file before reaching the size threshold. S3 express itself imposes a limit of 10,000 appends per object, which may not suffice for systems where the size threshold for transferring data to standard S3 is higher. Additionally, downstream processes may still require systems to process and recombine files stored in standard S3 for various use cases. As a result, append does not inherently simplify code complexity.
The best-case scenario for append is that it could reduce some CPU and memory usage by eliminating the need to combine S3 Express files in memory. It would also save on the GET and DELETE call costs associated with fetching and deleting intermediary files. These are indeed tangible wins.
As it stands today though, append in S3 Express has very limited use cases.
Update
Since writing this post, S3 has introduced conditional updates, which address the previously mentioned issue. With these updates, S3 Express Append can now be safely utilized in distributed systems.